Kafka intro
Take a look at 'Kafka's component' from a bird's eye view
Article last updated: May 21, 2023
I watched and read some articles about Apache Kafka and decided to structure all knowledge in one place. If you are a newcomer in Apache Kafka I hope that all information below help you better understand the key terms and concept of Apache Kafka.
Table of content
- What is kafka
- Broker
- Event
- Topic
- Replication
- Partition
- Producer & Consumer
- Consumer groups
- Message Delivery Semantics
What is kafka
Apache Kafka® is an event streaming platform based on the abstraction of a distributed commit log. It uses pull model and has lots of use cases including pub/sub messaging, event streaming and etc. I like the following use case when microservice 'A' produces some events and send it to Kafka whereas microservice 'B' consumes messages produced by 'A' (this is most common use case at my current project 😃).
Developers love Kafka for its scalability, high reliability and wide community 🫂
Broker
Is a separate node in kafka cluster or simply - running Kafka process. Broker has short responsibility list in aim to be very straightforward: broker can write events to the partition, serve reads from consumer, replicate partitions between each other. They dont do any complicated computation or message routing.
Event | Message | Record
Before going further we need to determine what is an event in terms of kafka. Event is something ephemera and relatively small (< 1Mb). It could be a mouse event that your Vue.js app sends to the server, purchase record, some metrics from your smart teapot. Check out event structure below:
| Key | [Optional]: value that used by kafka to distribute message across the cluster |
| Value | Content of the Event, it’s just byte array |
| Timestamp | [Optional]: eEvent timestamp, if developer did not set this value manually it will be set by cluster during processing |
| Headers | [Optional]: user defined set of key-value pairs |
Usually for us events are represented in a human readable format like JSON or Protocol Buffer, but deep inside kafka everything is just a byte array.
Topic
Topics are created by grouping together similar semantic events in order. Simply put topic is an ordered log of events stored on disk. When consumer reads another one event from the topic - it won't be deleted unlike traditional messaging systems. Every topic can be configured to expire data after certain age. Topic could have zero, one or more producers along with zero, one or more subscribers. Each event in a topic has its own offset, see illustration:

Figure 1. Topic with six events
Do you remember that Kafka is based on the abstraction of a distributed queue commit log, isn't it? There are
few crusual points about it:
-
we can start reading events from some offset
-
we can write our events only to the end of the topic
-
if event was written to the log - it’s exceedingly difficult to make it un-happen
Partitioning
What if our ability to publish or read events from the topic were limited to the IO capabilities of a single server? Of course we can upgrade our server, but its just scaling up - not that good! Kafka has a great ability to scale out by breaking topic into multiple logs - partitions.
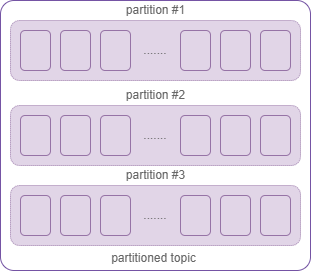
Figure 2. Topic with three partitions
Each partition will live on a separate node, so the load on the cluster node will be spread. This ability gives us almost infinite possibility to scale out. Kafka guarantees strong order ONLY WITHIN a topic partition. All events with the same key always hits into the same partition, events without key spread between partitions by Round Robin algorithm. We can easily add new partitions to the topic, but removing them is not very straight forward.
Replication
Is used for producing some durability guarantees. This is a mechanism to replicate topic partitions among other nodes in kafka cluster. We should discriminate leader (works with client) and follower replicas. Leader replica choosen automatically. In case of leader replica became unavailable kafka automatically pick-up a new leader among follower replicas, no effort from developer side required!
In general case consumers and producers communicate with leader replica. The system tolerate up to N-1 server failures, where N is a replication factor/replica count.
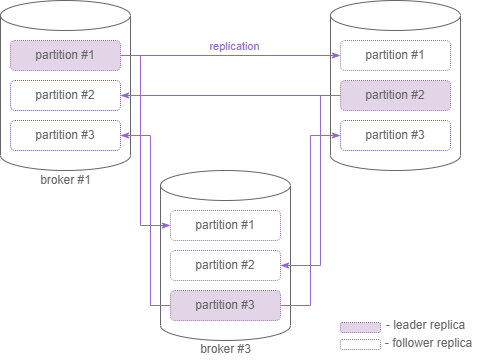
Figure 3. Replication factor three
In general producer communicate with leader replica.
Producer & Consumer
Producer Is an external process that sends events to the broker. Consumer is an external process that consumes events from Kafka topic. There are tonns of different setting for producer and consumer, it’s better take a look at documentation.
Consumer groups
Consumers who are intrested in same information, i.e. topics - could be joined into consumer groups. Good example - several instances of your application running in parallel. When multiple consumers are subscribed to a topic and belong to the same consumer group, each consumer in the group will receive messages from a different subset of the partitions in the topic.
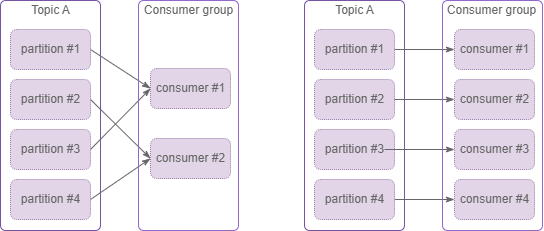
Figure 4. Consumer group
Keep in mind that number of consumers in consumer group greater than number of the partition does not make sense. In case below consumer 5 will idle…
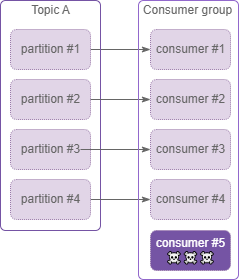
Figure 5. Consumer group with idle consumer
Take a closer look at: Kafka Consumers, Choose the number of topics
Message Delivery Semantics
Let's start from sending an event to the broker. There are three possible guarantees that could be provided:
at most once- event may be lost (≤1)at least once- event may be redelivered (≥ 1)exactly once- event delivered once (=1)
In case of at most once (acks mode 0) producer won't wait for broker acknowledgement, so event could be lost
somewhere.
In other scenario at least once (acks mode 1) producer will wait successful acknowledgement from leader replica, so we
have quite high delivery guarantee. Event still could be lost. This is a most used acks mode. Finally, 'exactly-once'
(acks mode -1) producer will wait acknowledgement from the leader replica and all in-sync replicas.
Ok, we send an event to the broker, but we have not handled it on consumer side. In general, we have same problem here:
at most once- event handling may be lost (≤1)at least once- event could be handled many times (≥ 1)exactly once- event handled only once (=1)
In case of at most once (auto commit mode) consumer will send successful commit right after event was received from
broker, but not handled! So We can receive the event but not have enough time tio handle it before consumer goes down.
In at least once (manual commit) semantic consumer will send successful commit manually. But what if we handle the
event properly and after that server goes down? When server recover we will get the same event. To handle event
exactly once we need to use manual commit mode with idempotent consumer or use custom commit offset management.
That's it, old sport! Thanks to reading up to the end 🙇
P.S. I recommend you watch the whole playlist from Kafka101 course along with reading Apache Kafka documentation.