CNN Steganalysis
Take a look into machine learning in steganalysis problem [part 1]
Article last updated: October 2, 2021
In this article, we are going to speak about the theoretical part of steganography detection based on convolutional neural network (CNN). At the end of this 'course', we expect the own built network will be able to classify an input image into two separate categories:
- Cover image - a 'pure' image
- Stego image - an image with embedded data (HUGO embedding algorithm)
What we need
Well, to learn our CNN we need some basic knowledge in machine learning and programming. I propose to use the following tools:
- Python as a main programming language
- PyTorch as a machine learning framework
- Google colaboratory as a platform for learning neural network
- BossBase v.1.01 as a dataset for learning neural network
Introduction to steganography and steganalysis
Steganography in its modern form is a private communication technic between two or more hosts. At the same time the fact of data exchange is hidden from prying eyes. Seems that the nodes just exchange images, but under the hood the image with a cute cat can hide the secret message.
Modern steganography techniques allow us to hide the data inside different digital data sources (containers): audio, image, video files. But most common way - using image container.
In parallel with the development of new steganography techniques the opposite direction has been developed. The opposite to steganography is steganalysis - it allows us to determine the fact of using steganography.
steganography wiki
steganalysis wiki
Convolutional neural network advantages
Of course for steganalysis purpose we can use more traditional methods like computation of Rich Models (RM), followed by classification using an Ensemble Classifier (EC). But in 2015 the first CNN for steganalysis appeared and its result was very close to the RM + EC classifier. Since then CNN has firmly established themselves in problems of steganalysis.
By mid of 2021 there are few proposed cnn with great classification results:
- SRNet - one of the first works on this topic
- Yedroudj-Net - some improvements like: HP-filters, batch normalization (BN) etc.
- Zhu-Net - proposed architecture uses Spatial pyramid pooling module to improve classification and other features
CNN for steganalysis
In this section we are going to look into specific features that are used in CNN and build our own architecture.
Building blocks for CNN
Analyzing proposed architectures can be inferred that each of them consists of three modules:
-
Pre-processing module.
Pre-processing module performs filtration operation with predetermined high pass filters (HPF). The fact is stego-signal is a poor signal, that can not be detected without any effort. So we need increase stego-signal level in our container. HPF is what we really need! It increases the stego-signal in the cover object.Using one or a few of HPF also enhances network convergence. Some of proposed architectures don't use any HPF and show high classification results. In the same time, these network uses much larger dataset, what leading us to longer learning time...
-
Convolution module
The main point here - extract the feature map from the input image. Usually, the module consists of few blocks (from 5 in Yedroudj-Net up to 11 in SRNet). Keep in mind, that each block consists of several operations, including the following: convolution, activation, pooling and normalization.Some of cnn uses separable convolutional as a first block in the convolution module. We use them to decrease number of parameters.
-
Classification module
The last block of the convolution module connected to the classification module. Usually it is a fully connected network. This module often ends with a specific function, that normalize network output between [0,1] - softmax function. In our case the output of our network will be the probability of belonging to one of the two hypothesis - cover/stego image.
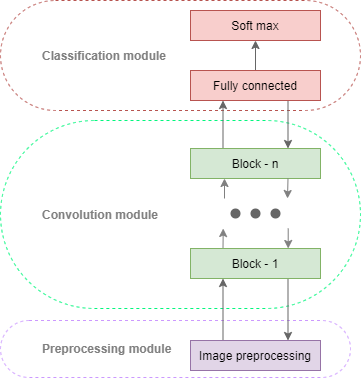
Figure 1. Common cnn modules
Architecture
Let's take the information above and put it all together. Full size image
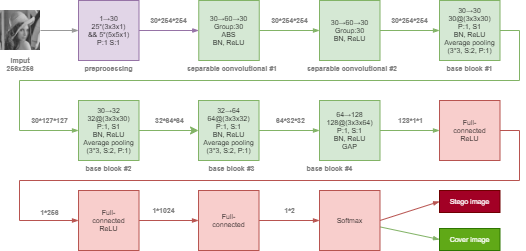
Figure 2. Possible architecture
An input - grayscale image 256x256 px (.pgm).
Preprocess module uses 30 basic high pass filters from SRM. It includes 25 filters 3x3 kernel size and 5 filters 5x5. Some existing architectures just extend 3x3 kernel to 5x5, but extended kernels will model residual elements in a big local region. We don't want it really... Thus, we use different kernel sizes, two parts of the residuals will summarize together and form the output. All 30 filters available here.
The first and the second blocks in the convolutional module is separable convolutional. In our scheme separable convolutional blocks consist of depthwise separable convolution 3x3 and pointwise connvolutional 1x1. After depthwise separable convolution there is Absolute value activation layer (ABS). The aim here - increase the signal/noise ratio. Also, it has other advantages. We will consider separable convolutional in the second part of this article. By the way here is a Pytorch implementation in advance.
In the development network we use 4 base blocks. All base blocks use kernels 3x3, it is possible to use kernels 5x5, but the first one should increase network nonlinearity, which significantly increases the possibility of presenting features. All blocks use BN, which is present in most of the new networks for steganalysis. Rectified Linear Unit (ReLU) is used as activation function. Blocks 1-3 use average pooling and finally block 4 use Global Average Pooling (GAP). GAP is used instead of a fully connected layer and spread elements one by one for each feature map.

Figure 3. Possible base block structure
Classification module includes 3 fully connected layers with 256, 1024, 2 neurons in the corresponding layer. At the end of this module, softmax function is used.
Data preparation
Before the second part, you still need some data preparation.
- The original data source contains 10.000 grayscale images 512x512, but we have to shrink them to 256x256 for our network. Shrink script can be found here.
- Embed the payload into each image using HUGO algorithm. The HUGO algorithm implementation can be found here.
Conclusion
We took a look at the theoretical part of steganography detection based on convolutional neural network and formed common rules of developing CNN. I recommend check out all links above, to better understanding how it works. Well, we have done a lot and now ready for the second stage...
So, my congratulations if you reach the end of this article 🎉🎉🎉